
Google claims that Bard is bettering at math and programming

[ad_1]

Bard, Google’s beleaguered AI-powered chatbot, is slowly bettering at duties involving logic and reasoning. That’s in line with a weblog submit published at this time by the tech large, which means that — due to a way referred to as “implicit code execution” — Bard is now improved particularly within the areas of math and coding.
Because the weblog submit explains, massive language fashions (LLMs) comparable to Bard are primarily prediction engines. When given a immediate, they generate a response by anticipating what phrases are more likely to come subsequent in a sentence. That makes them exceptionally good e-mail and essay writers, however considerably error-prone software program builders.
However wait, you would possibly say — what about code-generating fashions like GitHub’s Copilot and Amazon’s CodeWhisperer? Properly, these aren’t general-purpose. Not like Bard and rivals alongside the strains of ChatGPT, which have been educated utilizing an enormous vary of textual content samples from the net, ebooks and different assets, Copilot, CodeWhisperer and comparable code-generating fashions have been educated and fine-tuned virtually solely on code samples.
Motivated to deal with the coding and arithmetic shortcomings typically LLMs, Google developed implicit code execution, which permits Bard to write down and execute its personal code. The newest model of Bard identifies prompts that may profit from logical code, writes the code “beneath the hood,” exams it and makes use of the outcome to generate an ostensibly extra correct response.
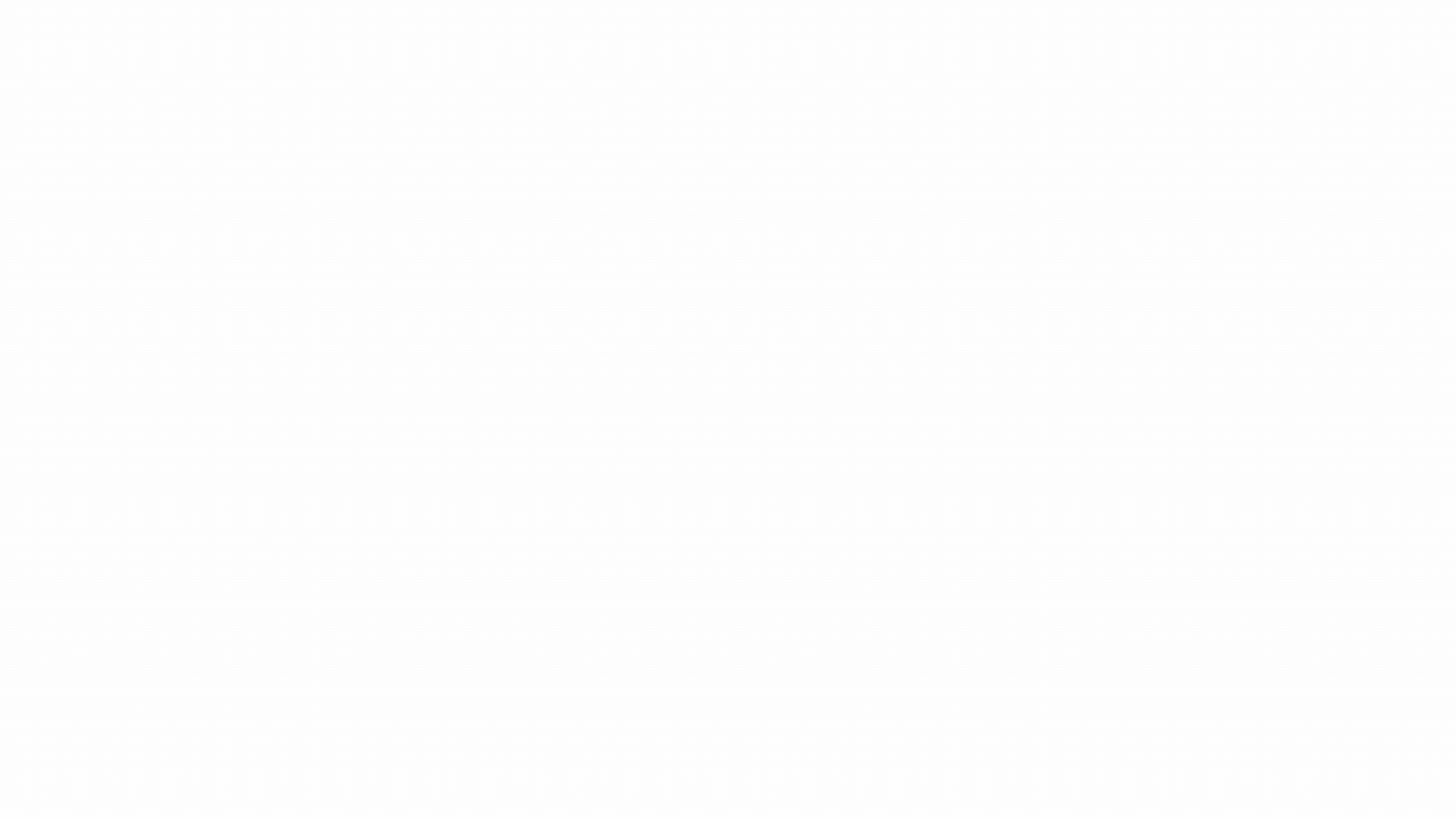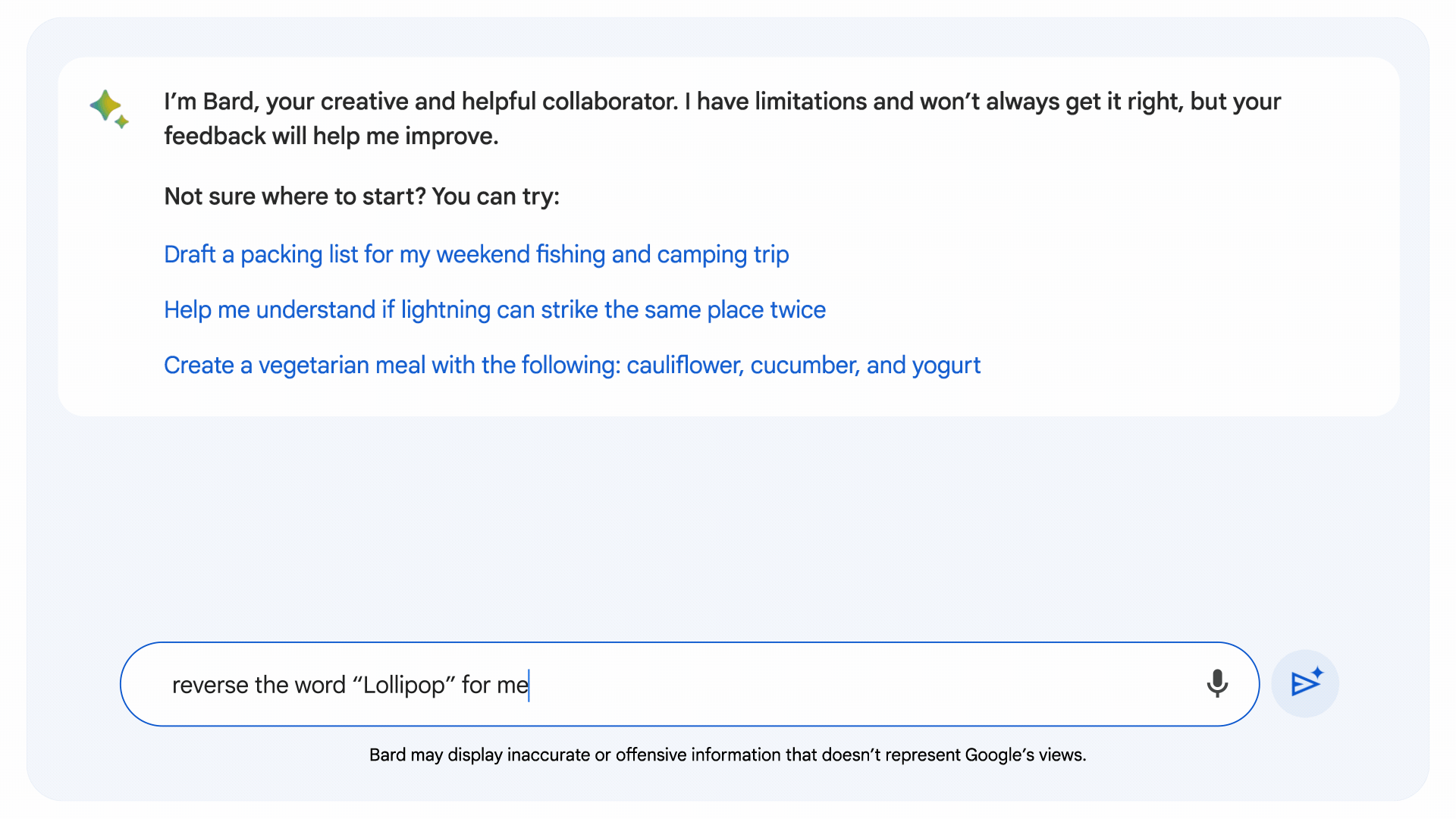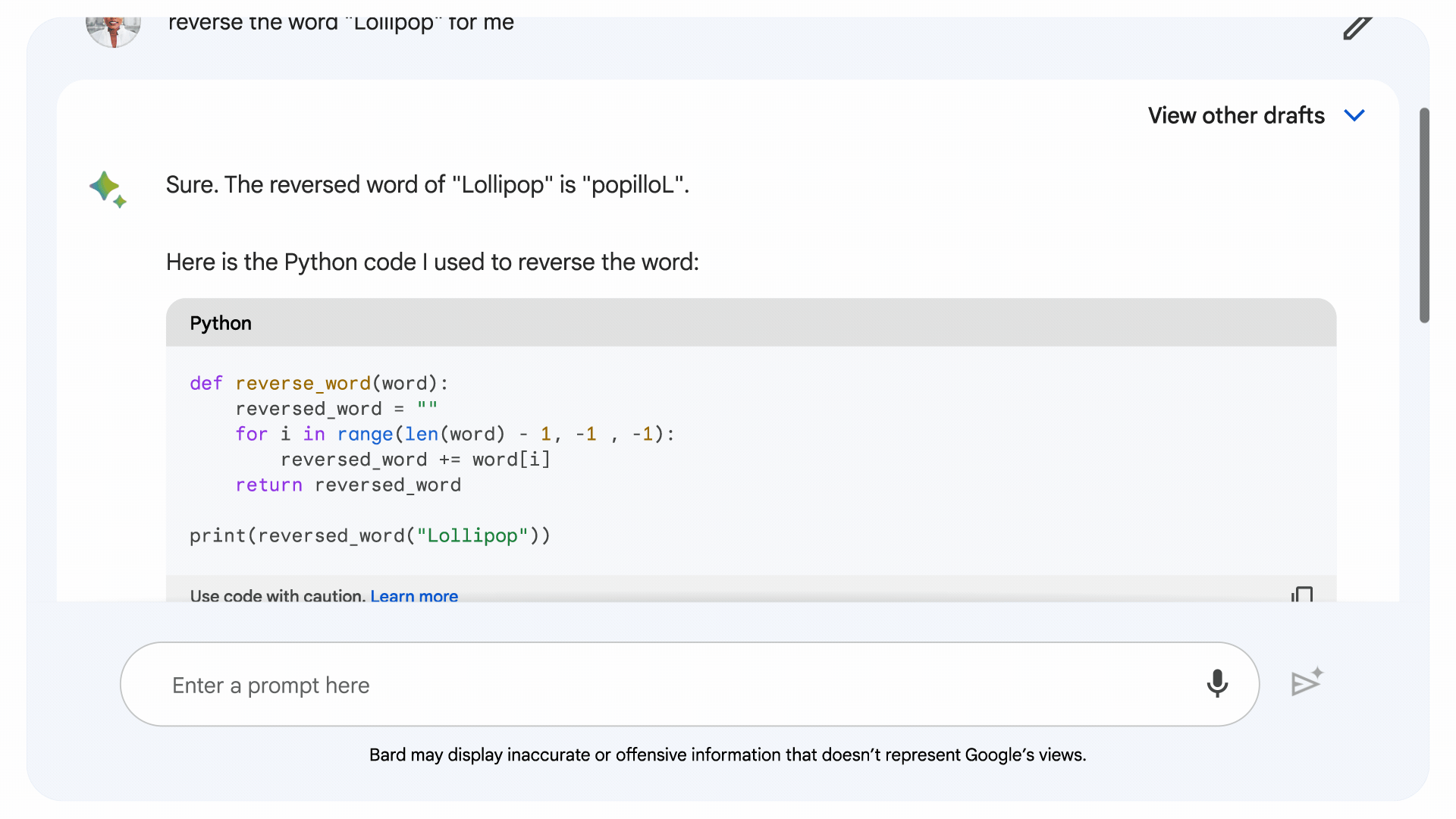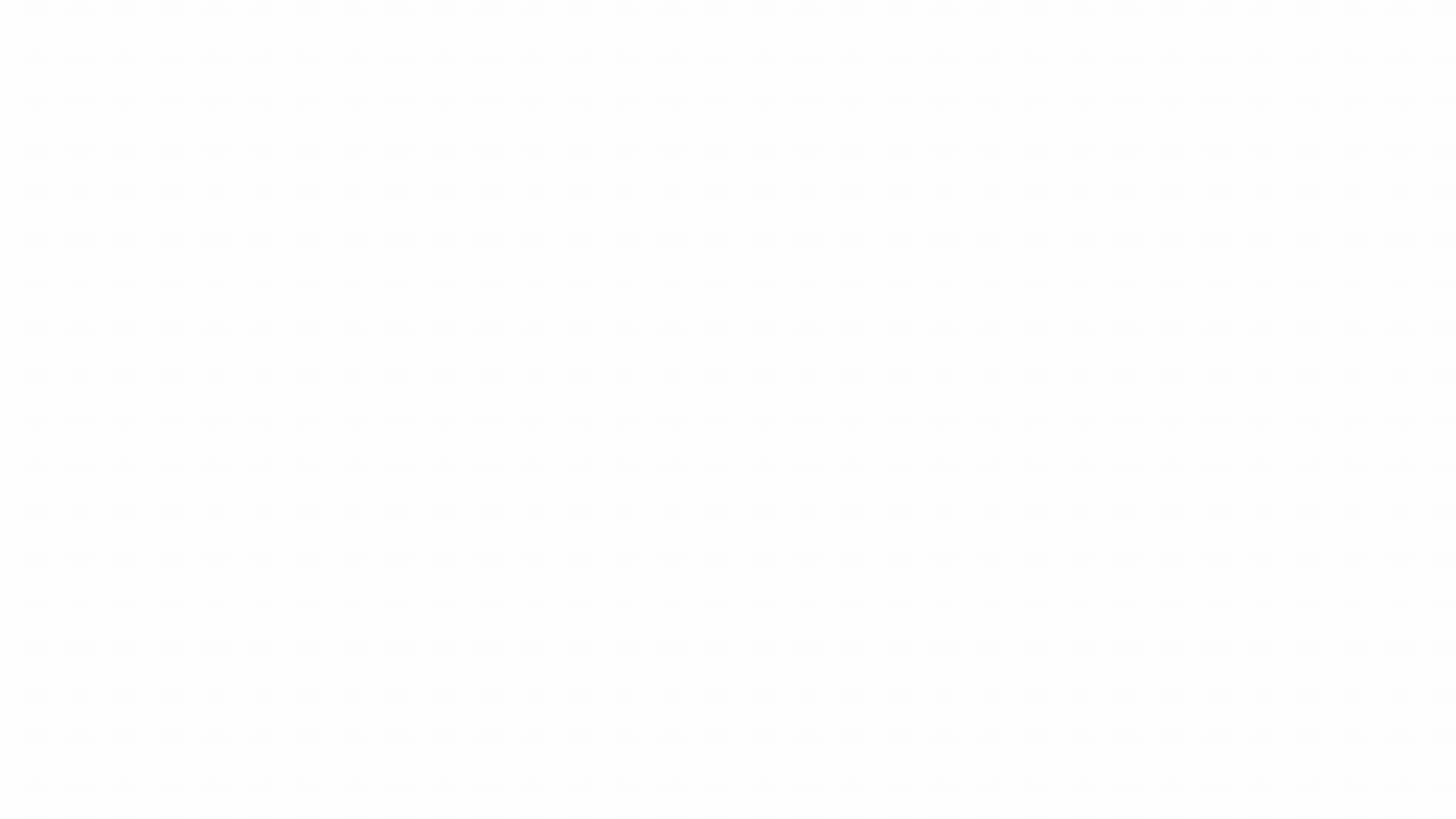
Picture Credit: Google
Primarily based on inside benchmarking, Google says that the brand new Bard’s responses to “computation-based” phrase and math issues have been improved by 30% in comparison with the earlier Bard launch. After all, we’ll need to see whether or not these claims stand as much as exterior testing.
“Even with these enhancements, Bard gained’t all the time get it proper — for instance, Bard may not generate code to assist the immediate response, the code it generates could be fallacious or Bard could not embody the executed code in its response,” Bard product lead Jack Krawczyk and VP of engineering Amarnag Subramanya wrote within the weblog submit. “With all that stated, this improved skill to reply with structured, logic-driven capabilities is a vital step towards making Bard much more useful.”
When Google launched Bard earlier this yr, it didn’t evaluate that favorably to the likes of Bing Chat and ChatGPT. Certainly, the rollout was a little bit of a catastrophe, with a Google advert that includes a fallacious reply by Bard — briefly tanking the corporate’s inventory by 8%.
Reportedly, a number of Google workers who examined Bard previous to its launch raised severe considerations to the search large, with one individual calling it a “pathological liar” and one other deeming it “worse than ineffective.”
With implicit code era and different enhancements, like assist for brand spanking new languages, multimodal queries and picture era, Google’s responding to criticism — and trying to show the state of affairs round.
Whether or not it’ll be sufficient to maintain up with the main generative AI chatbots within the house, although, stays to be seen. Not too long ago, Anthropic launched an AI chatbot mannequin with a enormously expanded “context window,” which permits the mannequin to converse comparatively coherently for hours and even days versus minutes. And OpenAI, the developer behind ChatGPT, has begun supporting plugins that supercharge ChatGPT with exterior data and expertise.
[ad_2]
Source link



